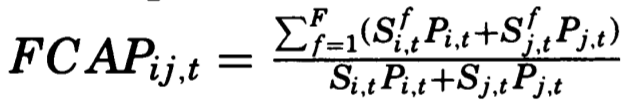Empirical Cross-Sectional Asset Pricing
Stefan Nagel. “Empirical
Cross-Sectional Asset Pricing” The Annual Review of Financial Economics (2013) 5:167-199.
The author reviews research in
several aspects of empirical cross-sectional asset pricing. Other posts here have
and will highlight papers which touch on some of them, so I summarize only a
couple of general themes.
There are approaches to
cross-sectional asset pricing which distinguish explanations for why investors
price assets the way they do and approaches which do not. “The economic content
of pricing models is … in the restrictions that they impose on the [stochastic
discount factor].” Ad hoc factor models and production-based models, while
useful in cross-sectional tests, do not rely on investor preferences for their
restrictions on the SDF and, so, do not explain the “why”. Rational
(consumption-based, long-run risk) as well as sentiment-based tests based on
theoretical restrictions on investor preferences give them a higher degree of
economic content. Frictions and liquidity risk can cause rational models to fail,
but studies in these areas provide evidence for “why” assets are priced the way
they are. That is, additional risks exist for which investors rationally
require additional return in order to bear the risk.
A significant amount of
cross-sectional asset pricing research is centered around finding deviations from
accepted models (anomalies). Recent studies have urged caution in this pursuit,
however. The possibility for data snooping, where some spurious anomalies are
randomly found to be significant, is an ever-present problem. Adjusting
critical values and performing out-of-sample testing are ways suggested in the
literature to help attenuate the problem. However, the author notes that pseudo
out-of-sample testing is not necessarily a solution because data can be mined
to find significant result here as well. True out-of-sample testing is
necessary to lend validation to results. A true out-of-sample test occurs when
data is used that was not available or used for the original study. Some ways
this has been done in the literature is the use of data from different markets,
post-publication data of the same asset(s) used in the original study, and in
some cases even pre-sample data that became available after publication. It has
additionally been found that use of r-squared statistics as an indication of how
well a model or factor explain the cross-section of asset returns can be
misleading when the test assets have a low-dimensional factor structure.
Investor sentiment happens when
asset prices are evaluated under a subjective probability distribution. Its
effect on asset prices is persistent when this sentiment is correlated across
enough investors and there are significant enough risks to dissuade or prevent
sophisticated investors from taking opposite positions and driving prices back
to their fundamental values. Investor sentiment and rational explanations for
return predictability need not be mutually exclusive. Research in this area
focuses both on finding and testing empirical proxies for investor sentiment
and on investigating the limits to arbitrage preventing sophisticated investors
from correcting mispricing. Analyst forecasts, style fund returns, and mutual
fund inflows are a few examples of proxies used with some success as proxies
for investor sentiment.
Real world investors must learn about
the return generating process in real time. Therefore, return predictability
obvious to researchers in retrospect may not have been known or obvious to
investors. Out-of-sample testing on variables shown to have ability to predict
returns is one area of research into investor learning. For example, studies
have shown that there is a decay of predictability after the publication of
research about return predictors. The implication is that something not known to
real-world investors becomes known upon publication and they then move to
exploit it to the extent possible. Additional research has been done using pseudo
out-of-sample testing where early periods in the data are used as a training
sample to predict future returns. The author notes that investor learning does
not fall under rational expectations or sentiment.
Empirical cross-sectional asset
pricing research has come a long way and there is much yet to be explored. Many
avenues of research are fruitful, but the ones with the greatest economic
content are those which have something to say about the preferences of
investors because they offer insight into understanding not just what is
happening but “why” investors are pricing assets the way they are.